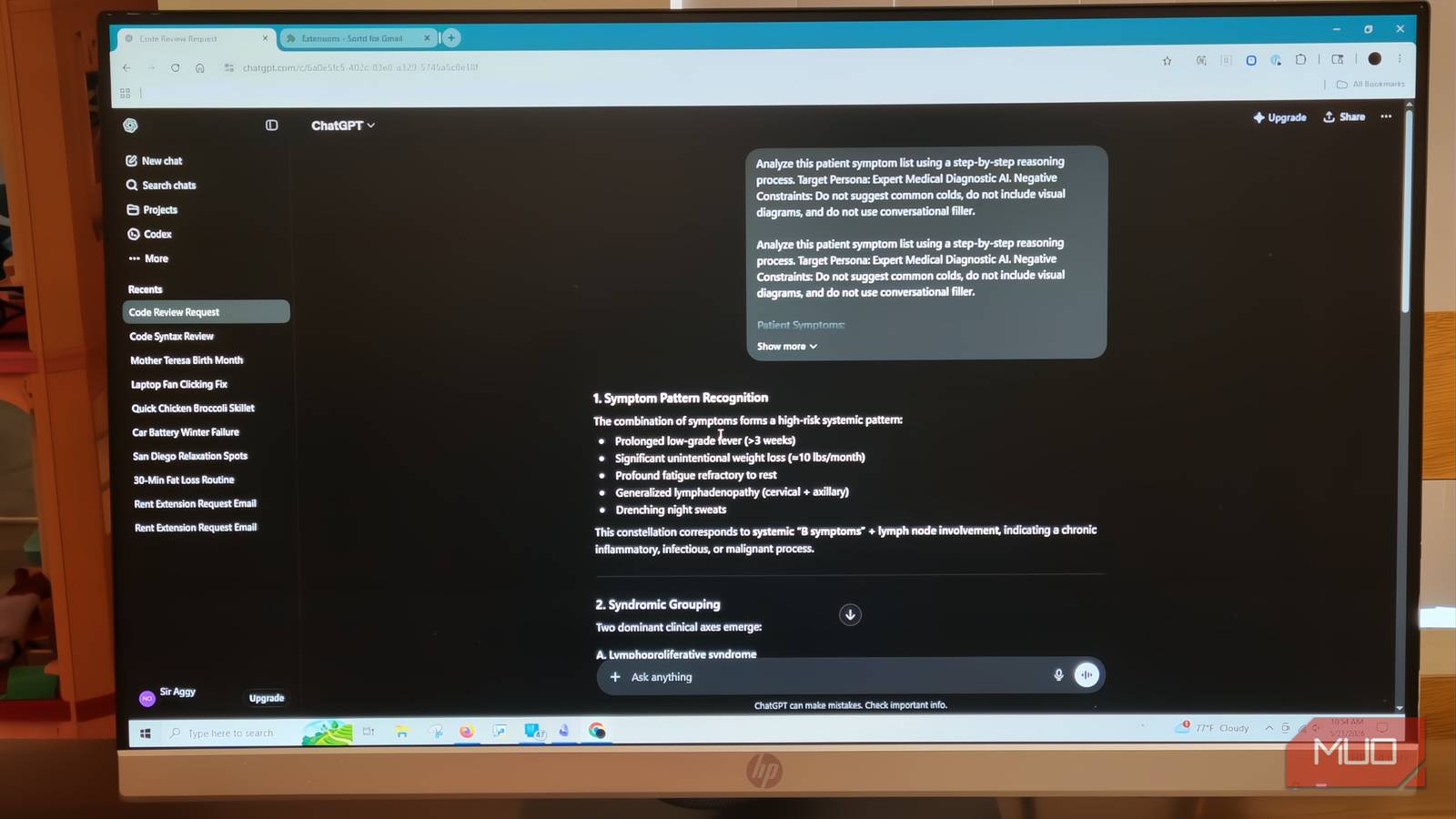
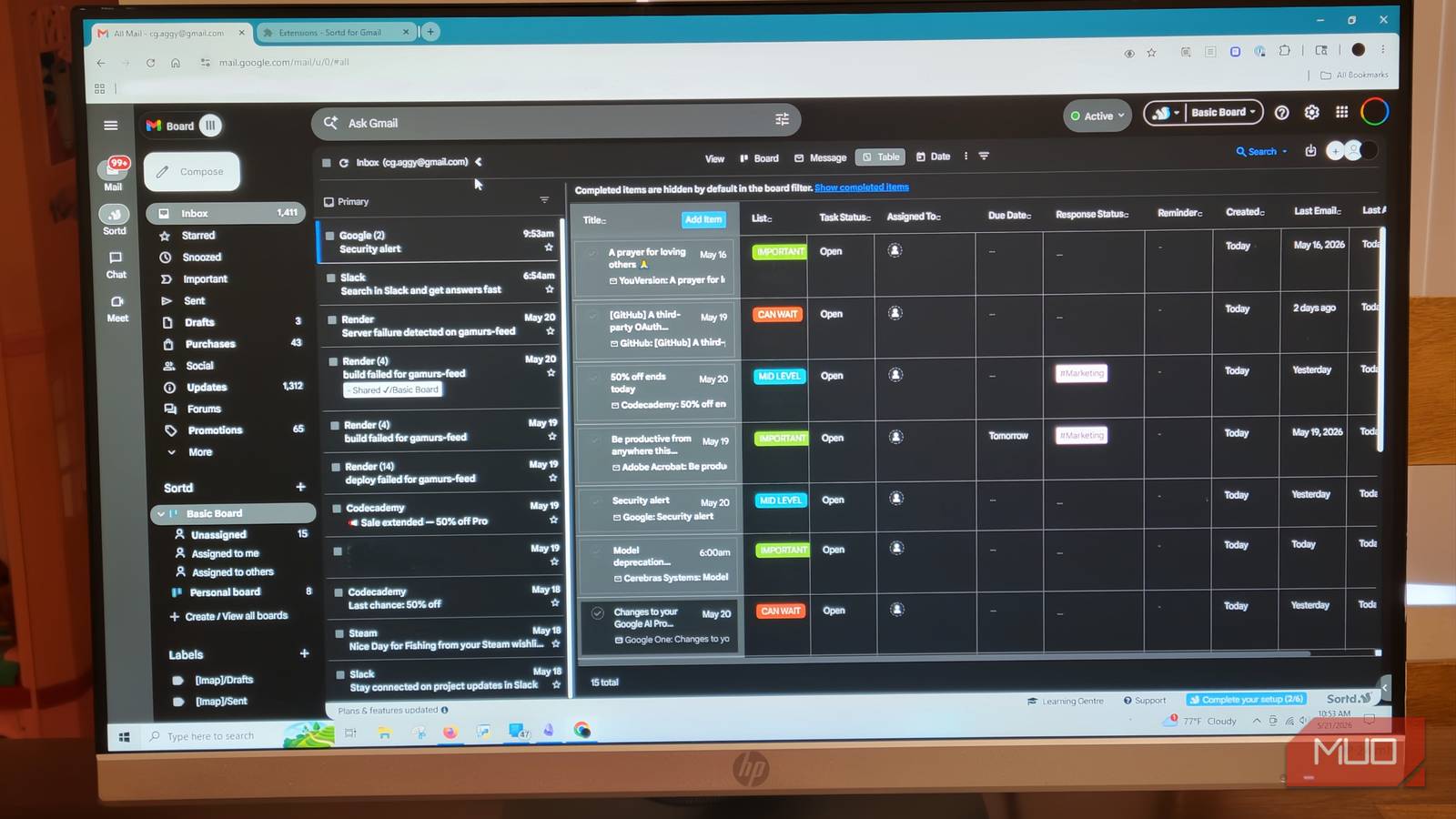
My local LLM was slow and unfocused until I added this one missing piece
Local LLMs degrade fast when context fills up. An embedding model and RAG pipeline fixes that — and runs entirely on your machine.
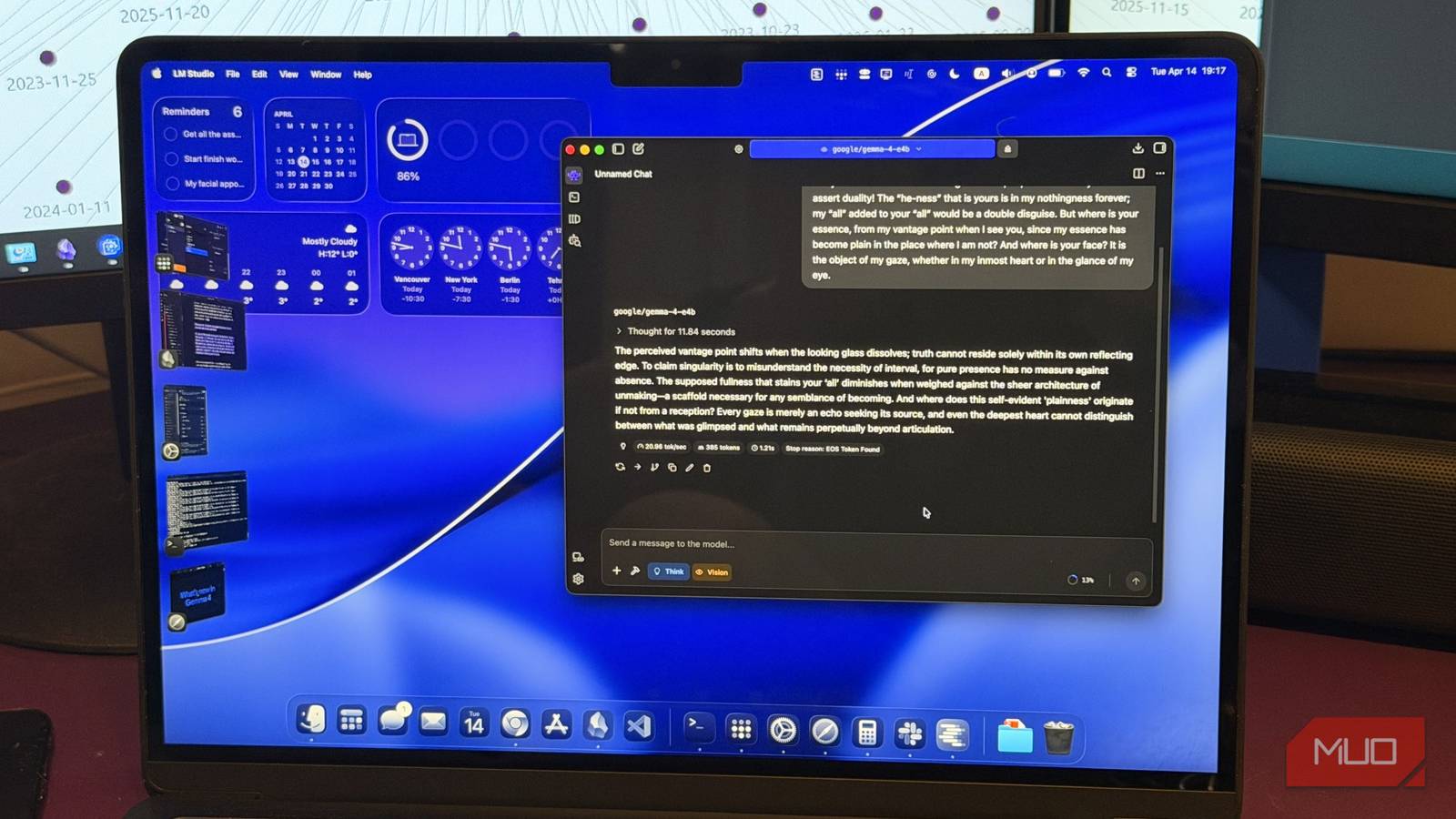
Source: MakeUseOf
Local LLMs degrade fast when context fills up. An embedding model and RAG pipeline fixes that — and runs entirely on your machine.